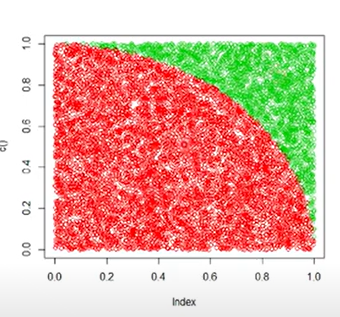
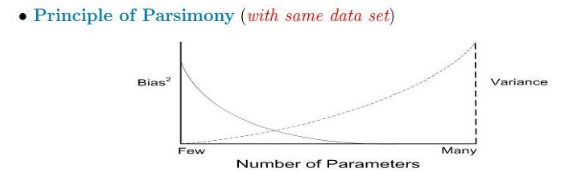
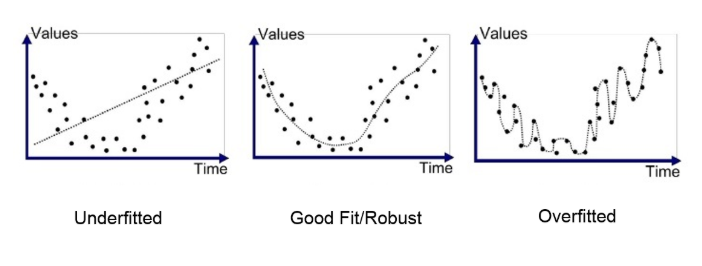
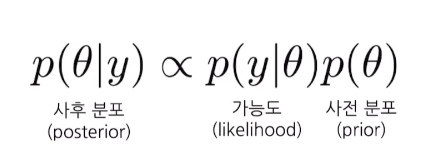진짜 생전 처음들어봄 ! 몬테카를로 알고리즘이랑 부트스트랩이 뭔지 그래도 알고 있어야 할 것 같아서 진짜 간단히 간단히 알아보려고 유투브보고 정리한 내용. 몬테카를로 시뮬레이션 몬테카를로 이름이 되게 생소한데, 모나코의 유명한 도박 도시 "몬테카를로"를 본따서 스타니스와프 울람(수소 폭탄 개발자)이 이름을 지었다고 한다. 알파고 관련 기사를 보여줬는데, 바둑은 경우의 수가 10의 170승올 막대해 컴퓨터가 모두 계산하는게 불가능하다. 그래서 난수를 발생시켜 그 샘플을 얻어서 답을 구하는 방식인 몬테카를로 방법을 사용했다는 기사였다. 즉, 몬테카를로 방법(Monte-Carlo Algorithm)은 수식만으로 계산하기 어려운 문제가 있을 때, 무작위 샘플을 얻은 뒤 그 샘플을 이용해서 답을 구하는 방법이다...