
pandas 라이브러리 중 EDA를 한눈에 볼 수 있는 라이브러리 발견 !
보고서 쓸 때나 데이터 확인할 때 쓰면 아주 좋을 것 같다.
pandas_profiling 이란 ?
딱 EDA할 때 보는 거 다 나온다. 이제 파이썬으로 하나하나 다 코드 안짜도 pandas profiling으로 해결 가능 ~

https://pypi.org/project/pandas-profiling/
pandas-profiling
Generate profile report for pandas DataFrame
pypi.org
살펴보기
전체 데이터 overview도 알려주고 각 변수마다 overview도 알려준다.
missing value도 알려주고 Zero 가 몇개인지도 알려줌. 오...완전 좋은데
일단 기능이 좋은건 확실


실습해보기
1. 설치하기
#설치
#pip 사용시
! pip install pandas-profiling
#conda 사용시
conda uninstall -c conda-forge pandas-profiling
#버전 확인
! pip show pandas_profiling

내 컴퓨터에서는 pandas version은 0.25.1 이 나왔고 pandas-profiling version은 2.8.0이 나왔다.
colab에서 하니까 계속 TypeError: concat() got an unexpected keyword argument 'join_axes'
이런 에러가 나서 pandas 를 1.** 대로 downgrade 하니까 잘 됨. (colab에서 했을때)
근데 왠만하면 colab 안쓰고 싶다... 계속 런타임 끊기고 느리고.. 나는 뭐가 좋은지 잘 모르겠음..
딥러닝 할때는 빠르게 잘되는건가...? 나는 그냥 주피터 쓰는걸로..

2. import 하고 profile 만들어보기
import pandas_profiling
from pandas_profiling import ProfileReport
#profile 파일 만들기
profile = ProfileReport(train,title="bio train data set")
#html 파일로 꺼내기
profile.to_file(output_file = "bio_train_profile.html")만들어지기까지는 조금 오래걸렸다. 하지만 그만큼 대기탈 수 있는 강력한 기능.
만들어지긴 만들어졌다.
근데 이 페이지를 넘겨볼 수 없었다....
76개 변수에 10000개 데이터였는데 컴퓨터가 멈춰서 볼 수 없었다...
회사 컴퓨터라서 좋은 사양이었는데도 볼 수 없었다. ㅠㅠ
그래서 train.sample(200)개만 가지고 profile 만들어봤는데도 안보임... 계속 컴퓨터가 멈춰서 어쩔수 없었음.
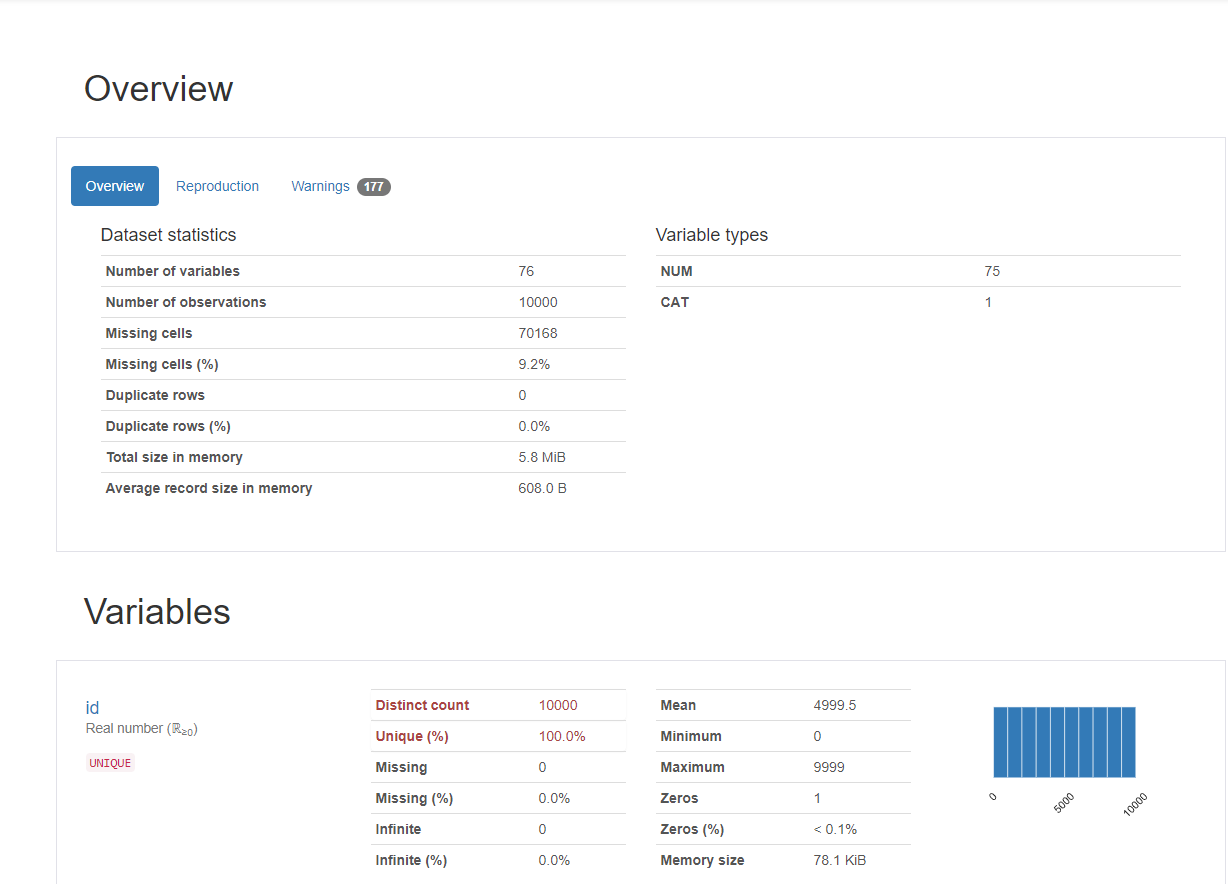
너무 좋은 기능이긴 하나 컴퓨터 성능이 좋지 못하면 볼 수 없는 pandas profile
sample로 몇개 뽑아서 자신의 컴퓨터 사양에 맞는만큼만 보도록 하자
사양 상관 없이 볼 수 있는 방법이 있을까 찾아봐야겠다.
'나는야 데이터사이언티스트 > PYTHON' 카테고리의 다른 글
| [Python]지도 데이터 시각화 - Folium 기초 실습하기 (0) | 2020.06.17 |
|---|---|
| [Python/pandas]데이터 결측치 처리하기(보간법/보외법) -pandas.DataFrame.interpolate (0) | 2020.06.13 |
| [Python] 결측치 시각화 하기 - missingno 종류 (0) | 2020.06.06 |
| [Python/seaborn] 데이터 시각화 - regplot, lmplot, catplot, swarmplot (0) | 2020.05.24 |
| [Python]문자열 양 끝 공백 또는 문자 제거 - strip(),lstrip(),rstrip() (0) | 2020.05.11 |