728x90
개인적으로 범주형 데이터의 전처리를 어떻게 해야하는지 정리하고 싶었는데
이번 기회에 한번 정리~~~
먼저 예시 데이터입니다
import pandas as pd
df = pd.DataFrame(
[['green','M',10.1,'class1'],
['red','L',13.5,'class2'],
['blue','XL',15.3,'class1']]
)
df.columns=['color','size','price','classlabel']
df

1. 순서가 있는 매핑
Size의 특성이 크기별로 순서가 있을때, 어떻게 전처리를 해야하는지 방법입니다
XL를 3
L를 2
M를 1
로 매핑했습니다
size_mapping = {'XL':3,'L':2,'M':1}
df['size'] = df['size'].map(size_mapping)
df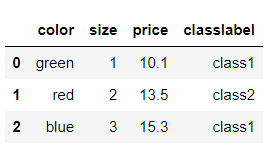
매핑된걸 다시 바꾸는 방법
inv_size_mapping = {v: k for k, v in size_mapping.items()}
df['size'].map(inv_size_mapping)2. 순서가 없는 매핑
순서가 없는 데이터 매핑 방법입니다
enumerate를 사용하면 0부터 시작~
import numpy as np
class_mapping = {label:idx for idx,label in enumerate(np.unique(df['classlabel']))}
df['classlabel'] = df['classlabel'].map(class_mapping)
df

3. Label Encoder
순서가 없는 매핑 방법에 enumerate를 사용하는 것 말고 scikit-learn의 preprocessing에도 전처리 하는 방법이 있습니다
from sklearn.preprocessing import LabelEncoder
class_le = LabelEncoder()
y=class_le.fit_transform(df['classlabel'].values)
y
4. Dummy 변수
보통 제가 이용하는 방식으로는 dummy 변수로 만들어 주는 것이었는데요
더미변수를 만드는 이유는
예를 들어 color 변수의 데이터가 blue, red, green이 있는데
이것을 각 0,1,2로 만들게되면
blue가 green 보다 작다, 크다라는 특성이 아닌데도 숫자로 변환되다보니까 그런 특성을 가지게 됩니다
이런것을 방지하기 위해 저는 보통 더미변수로 만들어서 사용했습니다.
더미변수 만드는 방법도 하나 기록~
pd.get_dummies(df[['price','color','size']])
반응형
'나는야 데이터사이언티스트 > PYTHON' 카테고리의 다른 글
| [Python] Anaconda3에 site-packages 폴더 없을때/위치 찾기 (0) | 2022.06.02 |
|---|---|
| [Python]Jupyterlab 가상환경 생성 및 커널로 쉽게 사용하기 (0) | 2022.05.10 |
| [Python]3차원 array를 DataFrame으로 만들기(3d arrays to DataFrame) (1) | 2021.11.13 |
| [Python]py 파일, ipynb 파일 바꾸기 (0) | 2021.10.25 |
| [Python]Dataframe datetime 날짜 차이 계산하기 (2) | 2021.08.18 |